The Internet Archive is a web site dedicated to building an “internet library,” an honest to God, actual library (recognized by the state of California and so eligible to receive federal funding) housing “cultural artifacts” from the internet. Perhaps the most notable of the IA’s collections is its archive of web pages. Since 1996, the IA has periodically taken snapshots of a vast number of web sites on the internet, anything its spider can get its crawly little legs on (save for sites whose robots.txt file blocks their archiving or owners request they not be archived). The archive can be easily accessed through the Wayback Machine, which allows users to enter a URL and view all the stored snapshots for that site.
Colin and I were looking at old versions of Google, back when it was but a fledgling search engine created by two guys from Stanford and not in control of the planet as it is today. I decided to look at the histories of the 100 most popular sites on the internet in the United States, as rated by Alexa. Below are some of the more interesting things that I found.
All of the screen shots I have taken are 1280×828, and most have file sizes in the 200-300 KB range (just so you are not surprised). In case the details matter to you for some reason, I used the October 16 nightly of Minefield v3.0a9pre on Mac OS 10.4.10 for each picture for consistency’s sake.
1). Yahoo!


October 17, 2007
Eleven years of progress in web design, and I think I actually prefer the page from 1996 to the one from today. I don’t remember ever visiting Yahoo! when it used the 1996 layout, but I definitely remember its next layout, active from 1997 to 1998.
One of the snapshots from April 17, 1999 has a banner advertisement regarding Yahoo! Pager (a predecessor of Yahoo! Messenger), and the fellow in the first two frames of the animation reminds me greatly of an old friend from Mac OS <10.
Yahoo!
Apple (black and white)
Apple (color)
2). Google

Who thought three shades of turquoise was a good idea, honestly.
3). MySpace
MySpace’s robots.txt file blocks the crawler. Why must they hate history? :(
Colin: At least people in the future won’t have to look at your horrible myspace layout.
5). Facebook
Facebook started in early 2004 as “Thefacebook” at thefacebook.com, and only became “Facebook” in 2005 after it purchased the domain facebook.com for a whopping $200,000. For many years prior to that, the domain was owned by AboutFace Software, which developed a web-based directory system.

6). Windows Live
Before November 1, 2005, live.com belonged not to Microsoft, but to Live Networks, Inc.

Live Networks now currently resides at live555.com.
7). eBay

Remember Beanie Babies?
8). Microsoft Network (MSN)

oh…
and if you are new to the Internet…
click here for our internet tutorial
Can I catch a virus by looking at a Web page? No, your computer cannot catch a virus by just clicking on a web page, even if it has graphics or plays movies, sound or 3D files.
Ahh, the good ol’ days.
13). Amazon.com
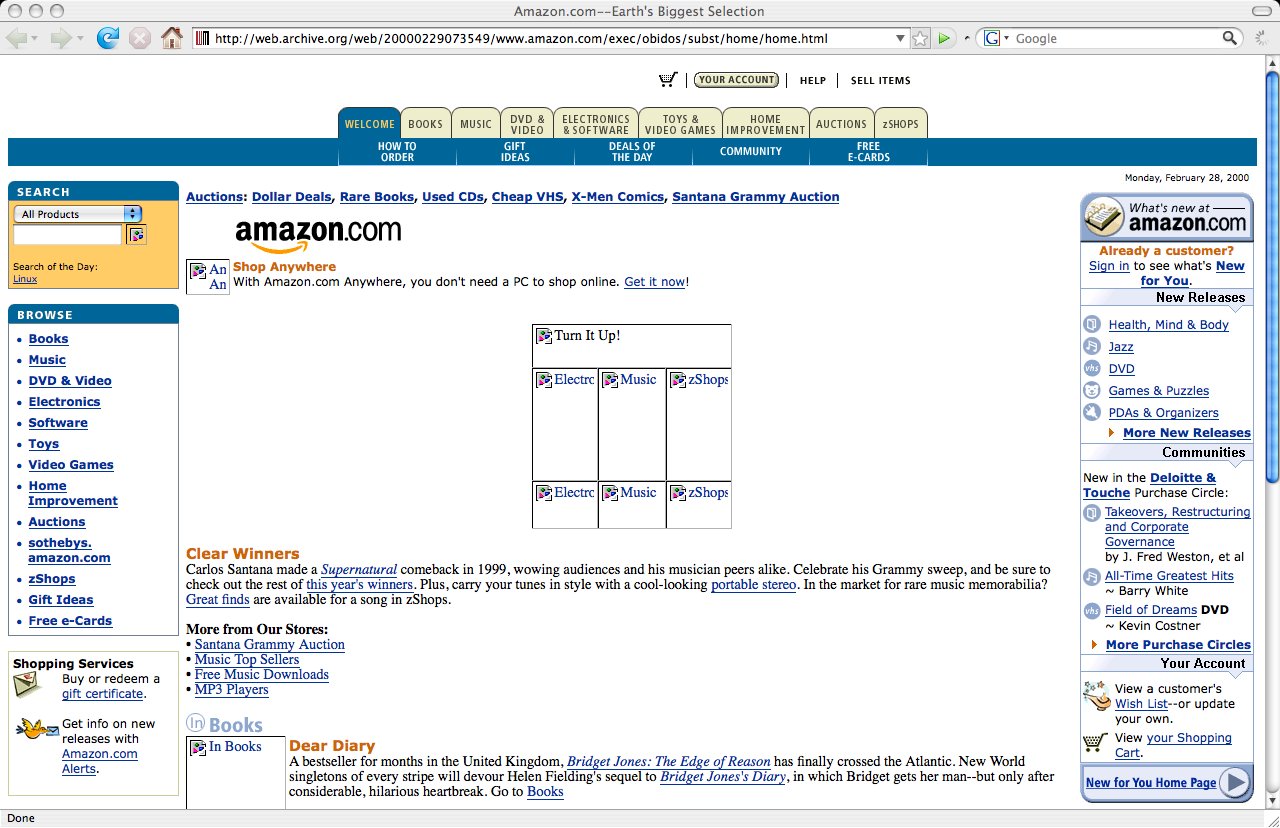

October 27, 2007
Amazon.com really hasn’t had a major change in their site layout in at least eight years. This layout extends all the way back to October 13, 1999, and possibly even later, but I chose the leap day version of the page to capture because it’s the earliest version of which the Internet Archive archived the navigation bar at the top.
Notice also that, at some point in time, the shopping cart icon in the page header switched directions.
15). Megaupload
This free file-hosting service is the second site to be blocked from being archived through robots.txt. Rapidshare.com is #23 on the list and it’s not blocked from archiving. I tried a few other sites not on the top 100 list like sendspace, YouSendIt, and File Den, and all were archived. I can easily see why Megaupload would not want their pages archived, though (at least the actual download pages, anyway), so I wouldn’t be surprised if I overlooked one or several file hosting sites that are similarly blocked from archiving.
16). Megarotic
Megarotic is an 18+ version of Megaupload, so it makes sense that it too is blocked. It’s also an 18+ version of Megavideo.com, which is #45 on the list and not blocked from archiving.
18). Photobucket image hosting and photo sharing


Chalk up another site that wasn’t always what it was now. Before being occupied by an image sharing service with an odd tan color scheme, it used to be a personal site.
19). The Internet Movie Database


I’m taking a different tack with this one; instead of showing off the differences in the front page like everything else, I’ve taken pictures of the IMDb top 250 movie list, as voted on by users. Notice the higher nerd influence in 1996 than in 2007.
24). Digg

Before Digg became the slophole of the internet, the domain used to belong to a record label of some sort. Unfortunately, only the front page works; none of the frames of the main page were archived.
27). The New York Times
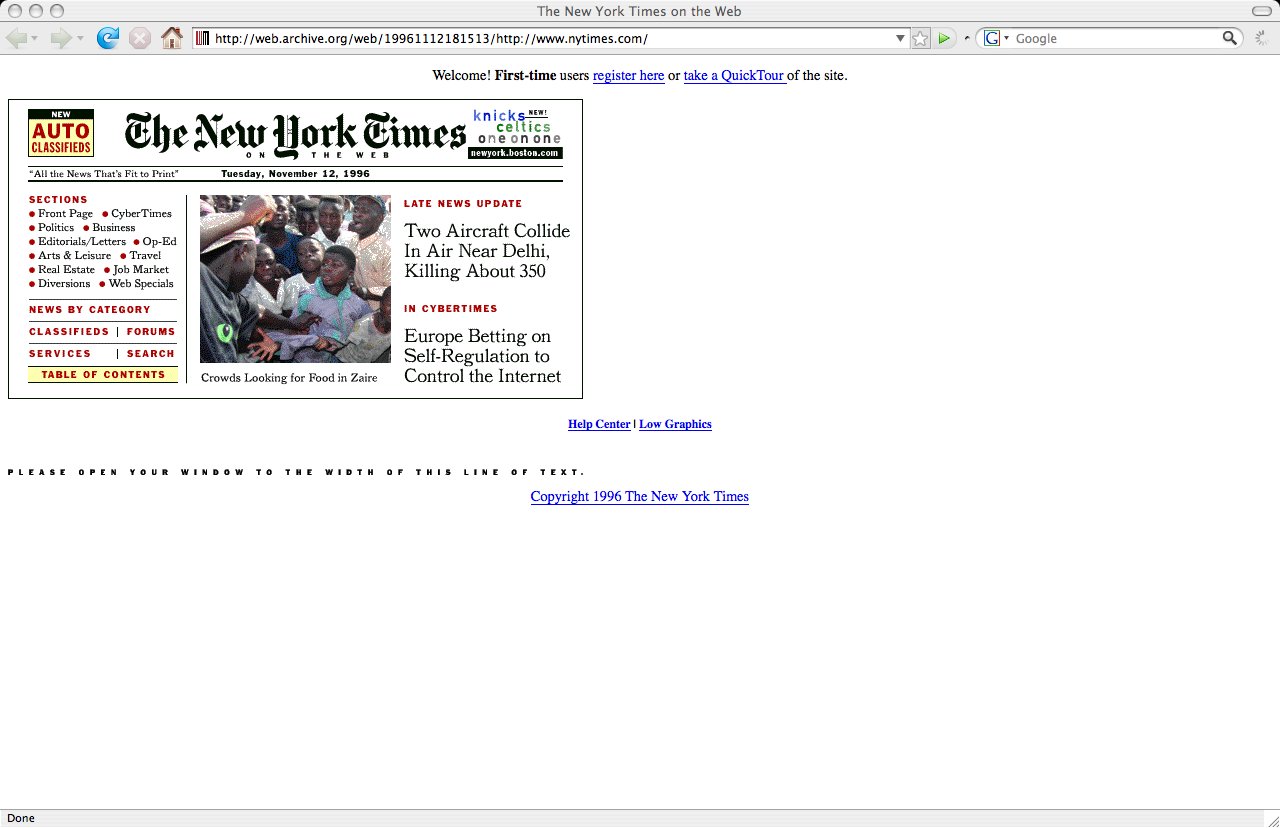
As you may be able to tell from the extreme amount of dithering in the text and photo in the main box of the page, the entire box is a single GIF image.
The spacing image on the bottom with the text “P L E A S E O P E N Y O U R W I N D O W T O T H E W I D T H O F T H I S L I N E O F T E X T .” is 575 pixels wide. This was of course a significant amount of screen realty back in 1996.
32). Apple Computer, Inc.




Going with four moments in time for this one because I am an Apple brainwasheeabsolutely love the progression in page design here.
34). Youporn.com
The fourth site blocked by a robots.txt file! This one is probably best not archived either. :(
37). Reference.com

Another one for the used-to-be-different file; until 1998, reference.com was a Usenet search engine.
47). ImageShack
Comic Sans! Welcome to the internet!
62). Target

Applix now currently resides at http://www.applix.com/.
64). Official Site of Major League Baseball
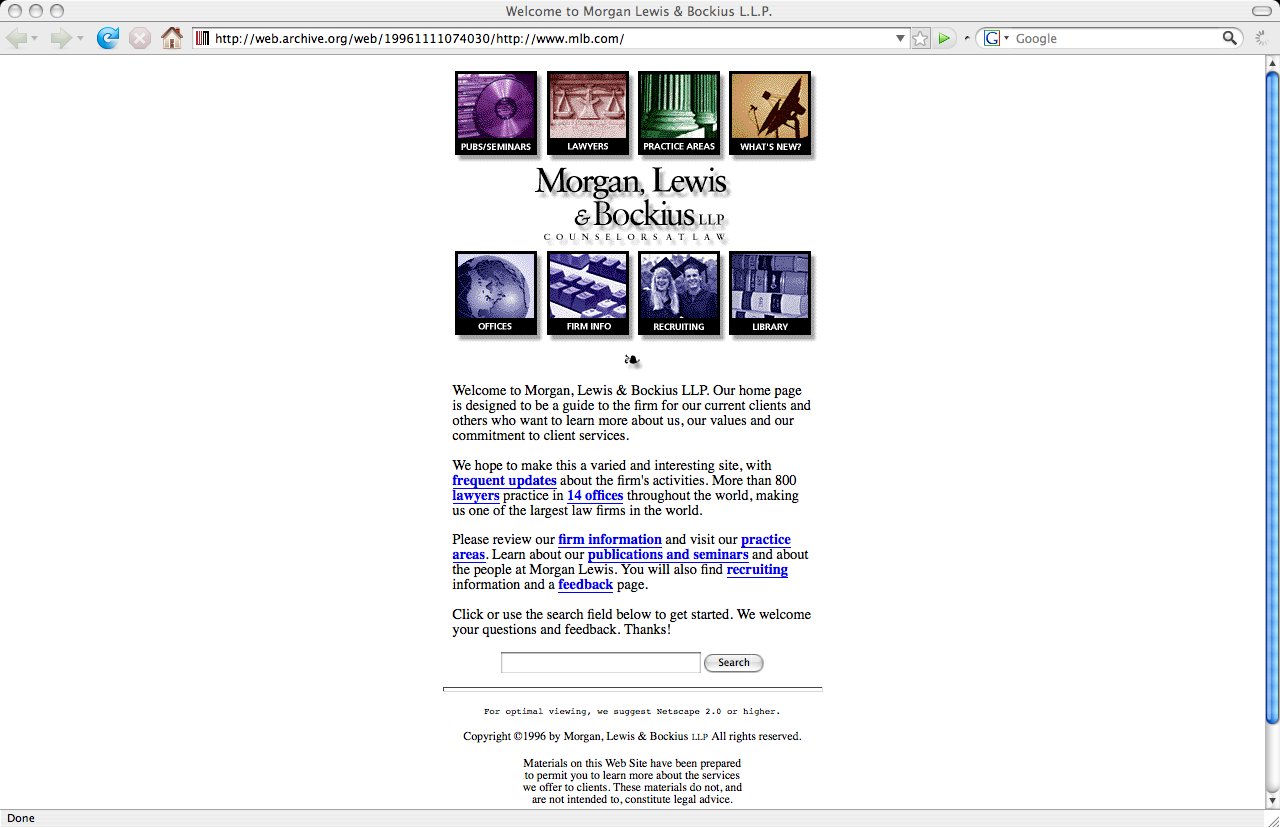
Morgan, Lewis, and Bockius, it makes sense, right? Anyway, they’re now at http://www.morganlewis.com/.
76). Break.com
Man, most of these down the stretch that I’m showing off are just site switches. :|

Before becoming one of the internet’s more popular time-wasting portals, the domain was previously owned by a Korean entrepreneur. Did anything result from his attempt to break the price to the competitive prices in the world? We may never know.
83). AOL Instant Messenger
Take a guess on whether or not aim.com always used to belong to AOL. Guess! You can do it!

Here’s a hint! http://www.aimtechnology.com/
85). DivX.com
Well yeah, it’s another one. But this one’s interesting!

Digital Video Express, or Divx, is not to be confused with the video codec DivX, the owning company of which now controls the domain divx.com. A Divx disc was an encrypted DVD which would only play in special DVD players and was able to be purchased for a much lower cost than that of a normal DVD. Once played, you were able to play a disc any number of times for forty-eight hours, after which it would become inactive and you’d have to pay a reactivation fee to be able to watch it again for another forty-eight; overall, the system was basically a rental movie system where you owned the discs. Divx was introduced by Circuit City and failed to catch on, being discontinued in 1999. Check this article from The DVD Journal for more info.
89). FanFiction.net
We’ve finally hit the fifth site blocked by robots.txt! This too is likely for the greater good.
97). 4chan.org
Sixth and final site in the U.S. top 100 blocked by robots.txt! And with good cause!
99). Geocities
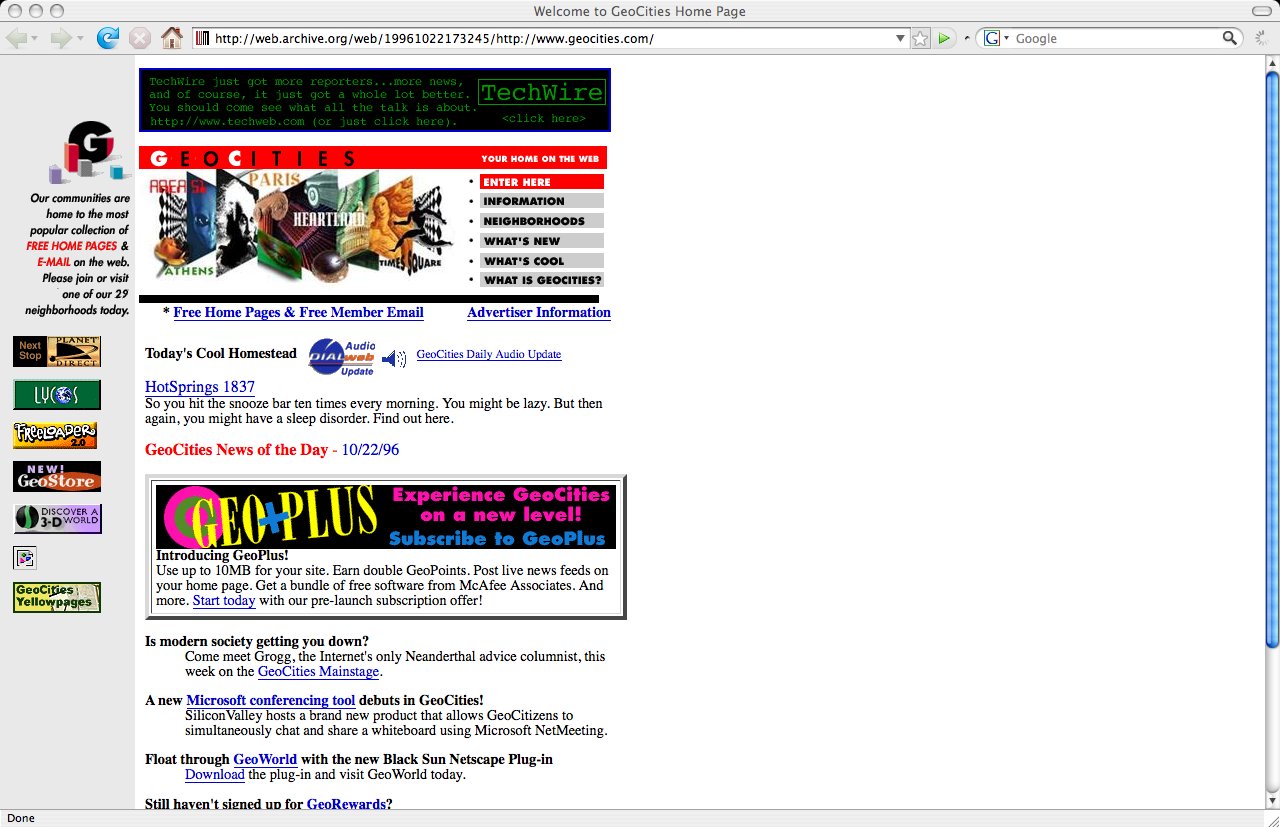
Before Yahoo! bought it, before you could choose to host your web site at http://www.geocities.com/xxxxxxxxx, there were neighborhoods and homesteads. The name “GeoCities” actually made sense. Ah, the good ol’ days.
I used to have a site at http://www.geocities.com/TimesSquare/Labyrinth/\d{4}, but, sadly, I’ve never been able to remember what the full address was. However, I’ve never felt it necessary to brute force the numbers to try to find it for two reasons. First, I have no guarantee the site was ever archived by IA. Second, I have a full copy of all the files on my hard drive, though. It used to be up at chz.fourx.org, and I’ll have them up again if quiteajolt.com ever emerges from limbo.
100). Icio.us
Rounding out the top 100 with a site that doesn’t exist! When Alexa calculates its rankings, it must add together all subdomain traffic to the total of the second-level domain, so all traffic to the popular bookmarking site del.icio.us is counted toward the SLD icio.us, despite the page at that URL being completely blank.
Post a Comment